Creating an XML representation for science data formats with XDF: cases, design and implementation.
Brian Thomas, Edward J. Shaya, Zhenping Huang
and Cynthia Y. Cheung
Astronomical Data Center
Goddard Space Flight Center/NASA
Greenbelt, Md. 20071
contact email: thomas@adc.gsfc.nasa.gov
ABSTRACT
XDF (the eXtensible Data Format) is an XML-based general science data format designed and maintained by the ADC (Astronomical Data Center). XDF may be used to describe both binary and ASCII scientific data and may alternatively serve as an XML wrapper for legacy science data files.
In this paper we will focus on a major aspect of XDF: its ability to describe existing legacy data formats. XDF may be achieve this by either directly describing the legacy data files and serving as a wrapper or, if greater sophistication and a higher level API is needed, by being extended in an object-oriented fashion to create a new hybrid science data format with the features of the legacy science data format.
We will present how XDF may generally be used to describe existing legacy data and cover a general outline of the steps needed to extend XDF to create your own XML/XDF-based data format. We will present several test cases including FITS and CDF and use them illustrate the problems and abilities of both approaches and to give examples of how to solve specific common problems.
I. What is XDF?
XDF is an XML-based general science data format designed and maintained by the ADC (Astronomical Data Center). XDF may be used to describe both binary and ASCII scientific data and may alternatively serve as an XML wrapper for legacy science data files. The XML heritage of XDF lends it many desirable features including the ability to describe both science data files locally or remotely, to be manipulated by and viewable with a wide variety of XML aware software (including browsers), to have universal validation via its DTD (Document Type Definition) or schema, and semantic mark-up of data products at all points in the science data cycle.
XDF (eXtensible Data Format) started as a part of a NASA/ AISRP program to research uses of XML in astronomical data archiving. XDF is a general scientific data format based on mathematical principles and is designed so that can be used throughout the scientific disciplines.
XDF has many important features including:
* hierarchical data structures (see figure 1),
* n-dimensional arrays merged with coordinate/field information,
* searchable ASCII meta-data,
* wrapping of existing data,
* serve as the basis for more specialized data formats in XML.
It is these lasts points which we will cover in some detail here; for more general information on XDF please refer to the URL http://xml.gsfc.nasa.gov/XDF.
II. Case: Wrapping Legacy Files
XDF is of course well suited to wrapping of legacy files which have minimal meta-data. Both ASCII and binary files may be wrapped. Consider the following data file ("file.dat"):
5050: Bright Star Catalogue, 5th Revised Ed. (Hoffleit+, 1991)
RA;DE;Vmag
h min s;deg arcmin arcsec;mag
A10,1x,5x,A9,5x,1x,F5.2,1x
EOH # end of header
00 05 09.9 +45 13 45 6.70
00 05 03.8 -00 30 11 6.29
00 05 20.1 -05 42 27 4.61
XDF can wrap this file using HREF/Entity mechanism native to XML. This mechanism contains 2 parts: an Entity declaration to the actual file ("file.dat") and reference to that entity by a <data> node within the XDF file. Because a portion of this file contains meta-data, a byte-offset will have to be applied to avoid reading non-data. This will appear within the XDF as an attribute "startByte"on the <data> node. Consider the following XDF representation of the above file the relevant portions have been highlighted:
<?xml version ="1.0"?>
<!DOCTYPE XDF SYSTEM "http://tarantella.gsfc.nasa.gov/xml/XDF_018.dtd" [
<!ENTITY table1 SYSTEM "file.dat">
]>
<XDF name="5050: Bright Star Catalogue, 5th Revised Ed. (Hoffleit+, 1991)">
<array>
<fieldAxis axisId="fields">
<field name="RA" description="? Right Ascension (Eq:J2000)">
<units>
<unit>h</unit>
<unit>min</unit>
<unit>s</unit>
</units>
<dataFormat>
<string length="10"/>
</dataFormat>
</field>
<field name="DE" description="? Declination (Eq: J2000)">
<units>
<unit>deg</unit>
<unit>arcmin</unit>
<unit>arcsec</unit>
</units>
<dataFormat>
<string length="9"/>
</dataFormat>
</field>
<field name="Vmag"
description="?Visual magnitude (1)">
<units><unit>mag</unit></units>
<dataFormat>
<float width="5"
precision="2"/>
</dataFormat>
</field>
</fieldAxis>
<axis axisId="rows" name="HR number">
<axisUnits><unitless/></axisUnits>
<valueList start="1" size="3"
step="1"/>
</axis>
<dataStyle>
<fixedWidth>
<fixedWidthInstruction>
<repeat count="2">
<readCell/>
<skip count="1"/>
</repeat>
<readCell/>
<skip count="1">
<newLine/>
</skip>
</fixedWidthInstruction>
<for axisIdRef="fields">
<for axisIdRef="rows">
<doInstruction/>
</for>
</for>
</fixedWidth>
</dataStyle>
<data href="table1" startByte="152">
</array>
</XDF>
The reader will note that the XDF representation is quite a bit larger than the original file (!). Alas, this is the price to be paid for universal parsing with XML; the XML tags somewhat less compact than many "home-brewed" prescriptions. Nevertheless, on reflection, the cost is small for the large datasets that are found throughout Astronomy; in many spheres of application (such as in archiving or science data processing), the number of bytes of meta-data (including XML tags) rarely exceed the number of bytes of data that usually exist in an astronomical dataset.
III. Case: Description of embedding XDF within an XML document.
For whatever reason, it may be desirable to embed science data (XDF) within a general XML document. For example, consider an archive document that refers to a published article from an Astronomical journal; in the archive document there are meta-data that refer to the several scientific tables of the original article and as well some meta-data that refer solely to published article itself.
XDF can be used to hold all of the meta-data, however, its generalized meta-data mechanism (via the <parameter> node) is less-suited to searching and/or may not have the desired descriptiveness the user desires for their article meta-data. Therefore, the user wishes to create their own meta-data tags and embed the science table data/meta-data within the overall document using XDF. The over-all document will have the following structure:
<?xml version="1.0"?>
<!DOCTYPE articleRootNode SYSTEM "myArticle.dtd">
<articleRootNode>
... meta-data referring to the article ...
<XDF>
... XDF meta-data refering to science table #1 ...
</XDF>
... more meta-data referring to the article ...
<XDF>
... XDF meta-data referring to science table # 2 ...
</XDF>
...
</articleRootNode>
XDF software will read this type of file with some small amount of effort. The steps are the following:
* Design the DTD (optional) : IF the user wishes to design a DTD for their XML document so that universal validation is supported, they must include all of the XDF rules. This is not as daunting as it sounds, as XML provides a mechanism for "inheriting" the XDF definitions easily in the new DTD. Within the new DTD the following 2 lines need be inserted:
<!ENTITY %XDF_DTD SYSTEM "http://xml.gsfc.nasa.gov/DTD/XDF_018.dtd">
%XDF_DTD;
Then, the user need only insert one or more ELEMENT rules specifying where the XDF nodes may go so, for example, later on in the DTD the user specifies:
<!ELEMENT tables (XDF)>
will allow placing an <XDF> node within any <tables> node that occurs within the article.
* Reading the new file with software : XDF software provides all of the functionality of the DOM (Document Object Model) in XML. In the Perl version, the user could specify the following program:
use XDF::DOM::Parser;
my $parser = new XDF::DOM::Parser ();
my $XDF_DOM =
$parser->parsefile("file.xml");
All of the DOM methods exist for manipulating ANY of the XML information the article contains (e.g. both XDF and non-XDF information), but DOM methods are quite cumbersome to use with XDF information, in particular, its difficult to add, remove or retrieve information contained within the XDF arrays. Therefore, XDF::DOM supports retrieval of the underlying XDF object(s) within the DOM. The following code may be used (Perl again):
# use DOM method to find all of the XDF
# nodes within the document
my @xdfNodes =
@{$XDF_DOM->getXDFElements};
# just pick off the first object for now
my $XDF = $xdfNodes[0]->getXDFObject;
# do something like adding data to the
# underlying XDF object,this *will* be
# reflected in the overall document when
# printed out later
$XDF->addData("1.0", $location);
IV. Case: Extension of XDF: Adding new metadata within XDF
One problem with XDF's <parameter> nodes is that they may not tightly enough control the meta-data. In some cases the user may wish to place additional restrictions on the meta-data and/or use their own tagging to promote readability. To illustrate, let us consider the FITS keyword for "observatory". This keyword (meta-data) may only occur once per table, however, if we store this information in "vanilla" XDF there is no control in the DTD to prevent additional parameter nodes being added with duplicate/overriding information.
To design a data format which defines additional meta-data within XDF, as is the case for FITSML, the user may choose to extend XDF. The steps to achieve this are not as trivial as for embedding, but are still strait-forward:
Design the DTD: The XDF node will be the root node. As for the above case of embedding, the DTD may simply inherit the XDF DTD rules with the following lines:
<!ENTITY % XDF_DTD SYSTEM "http://xml.gsfc.nasa.gov/DTD/XDF_018.dtd">
%XDF_DTD;
Additionally, in order to distinguish this data format from the vanilla XDF, the DTD should specify the following (in this case for "FITSML"):
<!ENTITY % XDF_TYPE "FITSML">
Extend the XDF Software: The XDF Parser *can* attempt to read the new data format, attempting to put the new, unrecognized meta-data within <parameter> nodes. This may or may not work well, depending on the complexity of the new meta-data. If the mapping between what the parameter node can hold and the new meta-data, this simplistic approach is apt to result in dropped information. Furthermore, even if the new meta-data are not dropped, the XML which is output will not mirror the input file (e.g. new meta-data are written as <parameter> nodes instead of using the original tags).
Thus, in all cases, to correctly deal with the additional meta-data in the new data format the user will have to extend the XDF package. This process is strait-forward:
= Declare a new data format class that implements XDF. Within this new class, the user should declare a method for loading the data format from file into an instance of this data format. The method which loads should call the XDF parser using an expanded set of ELEMENT handlers. These handlers will be used to shunt information to new classes which will hold the meta-data (rather than Parameter class).
= Add needed ELEMENT handlers to the XDF parser. Available handlers include startElement, endElement and CDATA.
= Add new classes to the extended package to hold the new meta-data.
This procedure is a fair bit more daunting than for the embedding case, and the user should only be considered by those wanting to provide long-term support for their new data format.Greater detail on this approach may be had by study of the Java FITSML package (see software download URL below).
V. Case: Translating to/from XDF using XSLT.
It may be that the legacy data format to be described has complexity or detail which does not map adequately to the XDF model. A current example of this is CDFML (the "CDF Meta-Language").
This case may be treated using a "big-guns" treatment of translating the XML science meta-data into canonical XDF via XSLT scripts.
Two significant downsides to this approach are obvious: XDF software will not natively read/write/manipulate the data file before translation and the XSLT script cannot translate untagged data into XDF (e.g. the user must either choose to formulate their data with XML tags or use the XDF prescription for untagged data).
VI. Summary
We have presented a number of ways in which XDF may describing existing data files and formats. In all cases, it is the type of meta-data which drives the user to adopting a particular solution (or combination of solutions). In no case can XDF
accommodate the translation of actual, untagged data (to do so would require specialized, non-XML based software and is thus outside the consideration of this article).
Nevertheless, we have presented a set of cases which are applicable to a large majority of the needs for formulating new XML data formats based on XDF.
We finish with a caution that XDF is a work in progress. The bounds which we have described here for creating new XML data formats may change within the future, as we further explore XDF and as new XML standards become available for use
in XDF. In particular, we anticipate changes to XDF to incorporate desirable features available in XML schema.
URLs
XDF Home page: http://xml.gsfc.nasa.gov/XDF/
ADC XML Project page: http://xml.gsfc.nasa.gov/A
XDF Software Download: http://xml.gsfc.nasa.gov/ADCSoftwareDownload.html
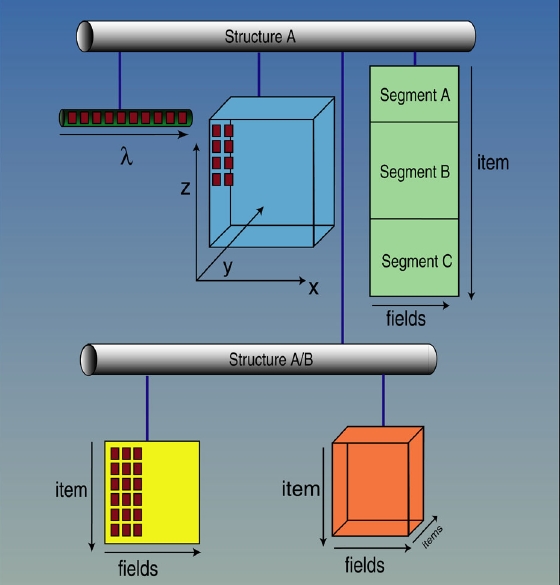
Figure 1. XDF hierarchical structure.